How to block AI Crawler Bots using robots.txt file
(www.cyberciti.biz)
from CynicusRex@lemmy.ml to privacy@lemmy.ml on 18 Aug 09:54
https://lemmy.ml/post/19285602
from CynicusRex@lemmy.ml to privacy@lemmy.ml on 18 Aug 09:54
https://lemmy.ml/post/19285602
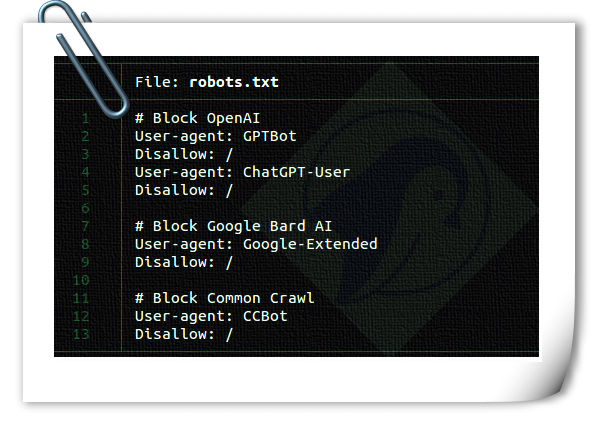
#privacy
threaded - newest
#TL;DR:
Of course, nothing stops a bot from picking a user agent field that exactly matches a web browser.
Nothing stops a bot from choosing to not read robots.txt
Indeed, as has already been said repeatedly in other comments.
Block? Nope, robots.txt does not block the bots. It’s just a text file that says: “Hey robot X, please do not crawl my website. Thanks :>”
Unfortunate indeed.
typically adhere. but they don’t have to follow it.
Is it a poor design if its explicitly a design choice to ignore it entirely to scrape as much data as possible? Id argue its more AI bots designed to scrape everything regardless of robots.txt. That’s the intention. Asshole design vs poor design.
Robots.txt is honor-based and Big Data has no honor.
This is why I block in a htaccess:
# Bot Agent Block Rule RewriteEngine On RewriteCond %{HTTP_USER_AGENT} (BOTNAME|BOTNAME2|BOTNAME3) [NC] RewriteRule (.*) - [F,L]This is still relying on the bot being nice enough to tell you that it’s a bot; it could just not.
Exactly. The only truly effectively way I’ve ever found to block bots is to use a service like Akamai. They have an add-on called Bot Manager that identifies requests as bots in real time. They have a library of over 1000 known bots and can also identify unknown bots built on different frameworks, bots that impersonate well known bots like Googlebot, etc. This service is expensive, but effective…
I wonder if there is an AI scraper block list I could add to Suricata 🤔
How does this differentiate between a user and a bot if the User Agent doesn’t say it’s a bot?
When any browser, app, etc. makes an HTTP request, the request consists of a series of lines (headers) that define the details of the request, and what is expected in the response. For example:
The thing is, many of these headers are optional, and there’s no requirement regarding their order. As a result, virtually every web browser, every programming framework, etc. sends different headers and/or orders them differently. So by looking at what headers are included in a request, the order of the headers, and in some cases the values of some headers, it’s possible to tell if a person is using Firefox or Chrome, even if you use a plug-in to spoof your User-Agent to look like you’re using Safari.
Then there’s what is known as TLS fingerprinting, which can also be used to help identify a browser/app/programming language. Since so many sites use/require HTTPS these days it provides another way to collect details of an end user. Before the HTTP request is sent, the client & server have to negotiate the encryption to use. Similar to the HTTP headers, there are a number of optional encryption protocols & ciphers that can be used. Once again, different browsers, etc. will offer different ciphers & in different orders. The TLS fingerprint for Googlebot is likely very different than the one for Firefox, or for the Java HTTP library or the Python requests package, etc.
On top of all this Akamai uses other knowledge & tricks to determine bots vs. humans, not all of which is public knowledge. One thing they know, for example, is the set of IP addresses that Google’s bots operate out of. (Google likely publishes it somewhere) So if they see a User-Agent identifying itself as Googlebot they know it’s fake if it didn’t come from one of Google’s IP’s. Akamai also occasionally injects JavaScript, cookies, etc. into a request to see how the client responds. Lots of bots don’t process JavaScript, or only support a subset of it. Some bots also ignore cookies, and others even modify cookies to try to trick servers.
It’s through a combination of all the above plus other sorts of analysis that Akamai doesn’t publicize that they can identify bot vs human traffic pretty reliably.
What if a bot/crawler Puppeteers a Chromium browser instead of sending a direct HTTP requisition and, somehow, it managed to set
navigator.webdriver = falseso that the browser will seem not to be automated? It’d be tricky to identify this as a bot/crawler.Oh there are definitely ways to circumvent many bot protections if you really want to work at it. Like a lot of web protection tools/systems, it’s largely about frustrating the attacker to the point that they give up and move on.
Having said that, I know Akamai can detect at least some instances where browsers are controlled as you suggested. My employer (which is an Akamai customer and why I know a bit about all this) uses tools from a company called Saucelabs for some automated testing. My understanding is that our QA teams can create tests that launch Chrome (or other browsers) and script their behavior to log into our website, navigate around, test different functionality, etc. I know that Akamai can recognize this traffic as potentially malicious because we have to configure the Akamai WAF to explicitly allow this traffic to our sites. I believe Akamai classifies this traffic as a “headless” Chrome impersonator bot.
I disallow a page in my robots.txt and ip-ban everyone who goes there. Thats pretty effective.
smart
Can you explain this more?
Imagine posting a rule that says “do not walk on the grass” among other rules and then banning anyone who steps on the grass with the thought process that if they didn’t obey that rule they were likely disobeying other rules. Except the grass is somewhere that no one would see unless they actually read the rules. The rules were the only place that mentioned that grass.
I like the Van Halen brown M&M version. smithsonianmag.com/…/why-did-van-halen-demand-con…
Did you ban it in your humans.txt too?
humans typically don’t visit [website]/fdfjsidfjsidojfi43j435345 when there’s no button that links to it
I LOVE VISITING FDFJSIDFJSIDOJFI435345 ON HUMAN WEBSITES, IT IS ONE OF MY FAVORITE HUMAN HOBBIES.
🤖👨I used to do this on one of my sites that was moderately popular in the 00’s. I had a link hidden via javascript, so a user couldn’t click it (unless they disabled javascript and clicked it), though it was hidden pretty well for that too.
IP hits would be put into a log and my script would add a /24 of that subnet into my firewall. I allowed specific IP ranges for some search engines.
Anyway, it caught a lot of bots. I really just wanted to stop automated attacks and spambots on the web front.
I also had a honeypot port that basically did the same thing. If you sent packets to it, your /24 was added to the firewall for a week or so. I think I just used netcat to add to yet another log and wrote a script to add those /24’s to iptables.
I did it because I had so much bad noise on my logs and spambots, it was pretty crazy.
This thread has provided genius ideas I somehow never thought of, and I’m totally stealing them for my sites lol.
Not sure if that is effective at all. Why would a crawler check the robots.txt if it’s programmed to ignore it anyways?
cause many crawlers seem to explicitly crawl “forbidden” sites
Google and script kiddies copying code…
You could also place the same page as a hidden link on your home page.
I doubt it’d be possible in most any way due to lack of server control, but I’m definitely gonna have to look this up to see if anything similar could be done on a neocities site.
Is the page linked in the site anywhere, or just mentioned in the robots.txt file?
Only in the robots.txt
Excellent.
I think I might be able to create a fail2ban rule for that.
Can this be done without fail2ban?
probably. never used it tho
How did you do it? Looking to do this on my own site.
My websites Backend is written in flask so it was pretty easy to add
Should be able to do it with Crowdsec
It isn’t an enforceable solution. robots.txt and similar are just please bots dont index these pages. Doesn’t mean any bots will respect it
This does not block anything at all.
It’s a 1994 “standard” that requires voluntary compliance and the user-agent is a string set by the operator of the tool used to access your site.
en.m.wikipedia.org/wiki/Robots.txt
en.m.wikipedia.org/wiki/User-Agent_header
In other words, the bot operator can ignore your robots.txt file and if you check your webserver logs, they can set their user-agent to whatever they like, so you cannot tell if they are ignoring you.
robots.txt will not block a bad bot, but you can use it to lure the bad bots into a “bot-trap” so you can ban them in an automated fashion.
I’m guessing something like:
Robots.txt: Do not index this particular area.
Main page: invisible link to particular area at top of page, with alt text of “don’t follow this, it’s just a bot trap” for screen readers and such.
Result: any access to said particular area equals insta-ban for that IP. Maybe just for 24 hours so nosy humans can get back to enjoying your site.
Problem is that you’re also blocking search engines to index your site, no?
Nope. Search engines should follow the robots.txt
You misunderstand. Sometimes you want your public website to be indexed by search engines but not scraped for the next LLM model. If you disallow scraping alltogether, then you won’t be indexed on the internet. That can be a problem.
I know that. Thats why I dont ban everyone but only those who dont follow the rules inside my robots.txt. All “sane” search engine crawlers should follow those so its no problem
Not if they obeyed the rules
No. That’s why they wrote “this particular area”.
The point is to have an area of the site that serves no purpose other than to catch bots that ignore the rules in robots.txt. Legit search engine indexers will respect directives in robots.txt to avoid that area; they will still index everything else. Bad bots will ignore the directives, index the forbidden area anyway, and by doing so, reveal themselves in the server logs.
That’s the trap, aka honeypot.
This article lies to the reader, so it earns a -1 from me.
Lies, as in that it’s not really “blocking” but a mere unenforceable request? If you meant something else could you please point it out?
That is what they meant, yes. The title promises a block, completely preventing crawlers from accessing the site. That is not what is delivered.
Is it a lie or a simplification for beginners?
Assuring someone that they have control of something and the safety that comes with it, when in fact they do not, is well outside the realm of a simplification. It’s just plain false. It can even be dangerous.
Lie. Or at best, dangerously wrong. Like saying “Crosswalks make cars incapable of harming pedestrians who stay within them.”
It’s better than saying something like “there’s no point in robots.txt because bots can disobey is” though.
Is it, though?
I mean, robots.txt is the Do Not Track of the opposite side of the connection.
Maybe? But it’s not like that’s the only alternative thing to say, lol
the word disallow is right there
Wow. A lot of cynicism here. The AI bots are (currently) honoring robots.txt so this is an easy way to say go away. Honeypot urls can be a second line of defense as well as blocking published IP ranges. They’re no different than other bots that have existed for years.
In my experience, the AI bots are absolutely not honoring robots.txt - and there are literally hundreds of unique ones. Everyone and their dog has unleashed AI/LLM harvesters over the past year without much thought to the impact to low bandwidth sites.
Many of them aren’t even identifying themselves as AI bots, but faking human user-agents.
Cloudflare just announced an AI Bot prevention system: blog.cloudflare.com/declaring-your-aindependence-…
When I changed my domain name I set this to on and then wondered why I couldn’t log into the Nextcloud desktop app.
robots.txt does not work. I don’t think it ever has - it’s an honour system with no penalty for ignoring it.
I have a few low traffic sites hosted at home, and when a crawler takes an interest they can totally flood my connection. I’m using cloudflare and being incredibly aggressive with my filtering but so many bots are ignoring robots.txt as well as lying about who they are with humanesque UAs that it’s having a real impact on my ability to provide the sites for humans.
Over the past year it’s got around ten times worse. I woke up this morning to find my connection at a crawl and on checking the logs, AmazonBot has been hitting one site 12000 times an hour, and that’s one of the more well-behaved bots. But there’s thousands and thousands of them.